
Newsletter un martes, yo te avisé:
Estuve enfermo todo el finde y recién hoy tengo energías para terminar de escribir este post.
La verdad es que me ceba bastante el tema que voy a tocar hoy.
Vas a aprender algo que muy pocos en el mundo están mirando.
Un tema del bleeding edge.
Hoy vamos a hablar sobre el Problema del Contexto.
Sus soluciones hasta hoy.
Las incógnitas que quedan sin responder.
Y obvio, sobre el final, cómo aplicar todo esto prácticamente.
Antes de que te me aburras y te vayas, te aseguro que esto te va a interesar.
Voy a intentar explicar un concepto hiper técnico en lenguaje humano y de forma visual. No importa si sos técnico/a o no, cuando termines de leer seguro te vas a llevar un gramo de curiosidad por esta área de AI que a mí me parece bastante hermosa.
Transformers
Para entender el Problema del Contexto (música dramática) necesitamos entender el principio de la historia: Los Transformers.
En junio de 2017, Google publicó un paper llamado "Attention is all you need", donde nace el Transformer.
Para nosotros, es una hermosa caja negra.

Lo que necesitás saber es que esta caja negra puede predecir la siguiente palabra si vos le das una secuencia de tokens (lo mejor es pensarlo como partes de una frase).

En su momento, esto fue una revolución total. Así nace GPT de OpenAI, y toda la revolución que estamos viviendo.
Antes de los Transformers, si vos querías procesar una frase, lo tenías que hacer palabra por palabra, secuencialmente. Esto tardaba mucho, era costoso, y además el sistema se olvidaba de lo que había leído bien bien al principio.
En especial si eran párrafos largos.
Los Transformers permitieron que todas las palabras se miren al mismo tiempo (paralelizar) y que se comparen con todas las otras palabras, generando relaciones entre ellas.
Todo muy bueno pero tienen un problema fatal.
Imagino viste la peli "50 First Dates" de Adam Sandler. Bueno, Lucy es un Transformer. Se despierta todos los días sin recordar el ayer, empezando de nuevo.
Lucy no se acuerda de tu conversación del otro día.
Lucy se olvida.

Adam Sandler tuvo una genial idea: Le grabó un video contándole toda la historia de su vida hasta el momento, y la obligaba a Lucy a verlo todas las mañanas.
Eso mismo pensaron los ingenieros de IA para que los transformers puedan tener algún tipo de continuidad en una conversación. Hicieron esto:
Llamada 1:
Input: [mensaje 1]
Output: [respuesta 1]
Llamada 2:
Input: [mensaje 1 + respuesta 1 + mensaje 2] ← copia completa
Output: [respuesta 2]
Llamada 3:
Input: [mensaje 1 + respuesta 1 + mensaje 2 + respuesta 2 + mensaje 3]
Output: [respuesta 3]
¿Qué podría salir mal? Bueno:
- La cantidad de input crece infinitamente. Eventualmente algo hay que cortar (cortamos lo más viejo) y el sistema se pierde de ese contexto.
- Cuantos más mensajes y respuestas, más tokens.
Acordate, el Transformer compara un token (parte de una frase) con todas las otras para medir relaciones entre tokens. Si hay 5x tokens, hay 5x comparaciones más. En el límite, esto explota y es inviable.
Lost in the middle
Además de esos dos problemas, que uno podría razonar, ocurrió uno que nadie esperaba.
Resulta que el modelo le prestaba más atención al principio y al final de textos.
Este modelo fue entrenado con grandes textos y documentos, infinitas veces.
Nosotros, los humanos, solemos poner lo más importante al principio y al final.
Y eso aprendieron estos modelos.
Entonces, se perdía la info del medio.
La ignoraban, quedaba cortada, llamalo como quieras.
En un paper, le dieron a una LLM 20 documentos y una consulta. Solo 1 de los documentos tenía la respuesta correcta, pero la posición del documento iba cambiando.
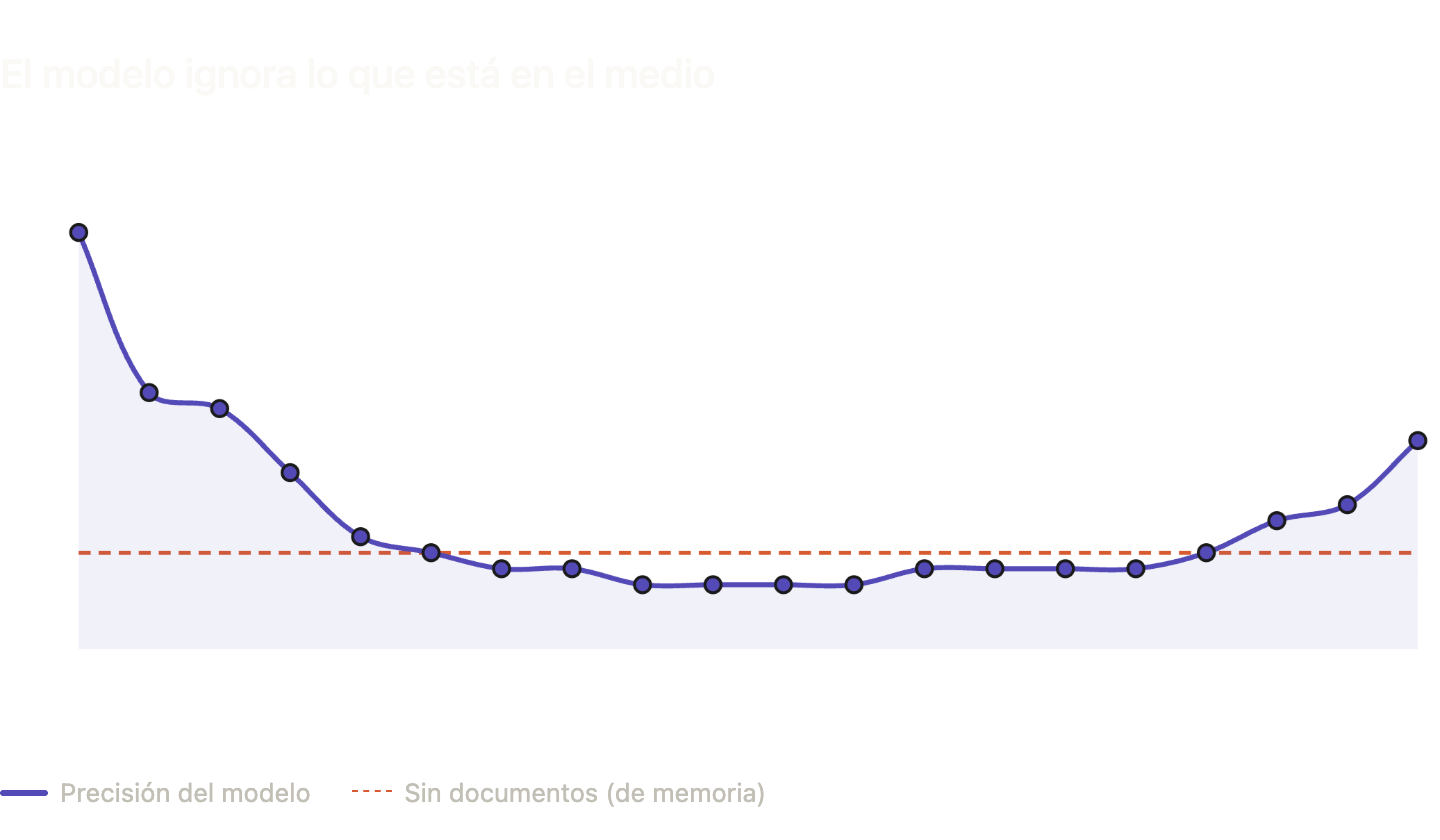
Locura, ¿no? U-shaped attention bias lo llamaron.
Con esta revelación logramos entender que no solo importa cuánto contexto le damos a un modelo, sino su orden.
Ya somos 100+.
En paralelo: RAG
Intento hacerla corta.
RAG (Retrieval-Augmented Generation) es una manera en que las LLMs pueden acceder al conocimiento de bases de datos externas o muy grandes.
Como si Lucy, cuando se despierta, tuviera un libro en su mesita de luz que detalla toda su vida hasta el momento.
Claro, ese libro es enorme y sería imposible de encontrar algo específico.
Si nuestro modelo (que usa Transformers por dentro) es esa caja negra, RAG es un imán que nos ayuda a inyectar la info correcta en el momento correcto.
Nos ayuda a encontrar el bloque de info que es relevante (el naranja) en un mar de bloques que no son tan relevantes.

Cuando vos le haces un prompt a una LLM, el sistema RAG agarra tu pregunta, entiende qué parte de la base de datos enorme es la que necesitas, y le da la info a la LLM para que te responda mejor.

Épico.
Ahora nuestro modelo incorpora ese bloque de conocimiento y nos da una respuesta integrada que tiene sentido con lo que preguntamos.

Pensá en todos los bots con los que hablás por Whatsapp.
Quizá el de algún hotel.
Ellos le dan toda la info de su hotel (cantidad de cuartos, horarios, servicios, etc) pero es demasiado para ponerlo todo en contexto a la misma vez.
En esos momentos, RAG for the win.
Si el usuario quiere saber si hay desayuno incluido, entonces RAG va a buscar todo bloque de info relacionado a un desayuno.
Fusión
Cuando sale el paper de Lost in The Middle, RAG ya existía hace 3 años.
¿Por qué RAG de la nada pasó de ser algo más a ser algo urgente?
Lost in The Middle demostró que los modelos se olvidan de las cosas que están en el medio, por lo tanto es mejor llenar el contexto con pocas cosas que sean relevantes: RAG.
Y de a poco, todo se va conectando...
El problema del Contexto
Acá se pone interesante la cosa.
RAG agarra un documento o una base de datos y lo separa en "bloques" de información. Peeero esos bloques pueden fallar.

Ahora, si vos le preguntas a una LLM: ¿Por qué le duele la panza a Tomas?
En una de esas encuentra el primer bloque, ve que no tiene contexto, busca en internet o alucina una explicación generalista de posibles causas.
Segunda opción: RAG encuentra el segundo bloque (puede variar según el phrasing de tu pregunta entre otras cosas) y entonces sabe que te operaste ayer.
Un resultado es PASS y el otro es FAIL.
En ambientes de producción, esto no es razonable. Un hotel no puede tener un 50% de sus consultas mal contestadas.
Por esto los chatbots que tenían LLMs detrás tardaron tanto en volverse mainstream.
Alucinaban un montón aunque la información estaba.
Estaba, pero mal particionada, sin contexto ni conexión a otros bloques.
Anthropic salva el día
En 2024 Anthropic mejora RAG con un sistemita llamado Contextual Retrieval. Recomiendo lectura de ese artículo para los techies de la audiencia, está bien explicado.
Básicamente descubrieron que agregar un pequeño contexto a cada bloque reducía casi un 50% los errores de las LLMs a la hora de buscar respuestas con RAG.
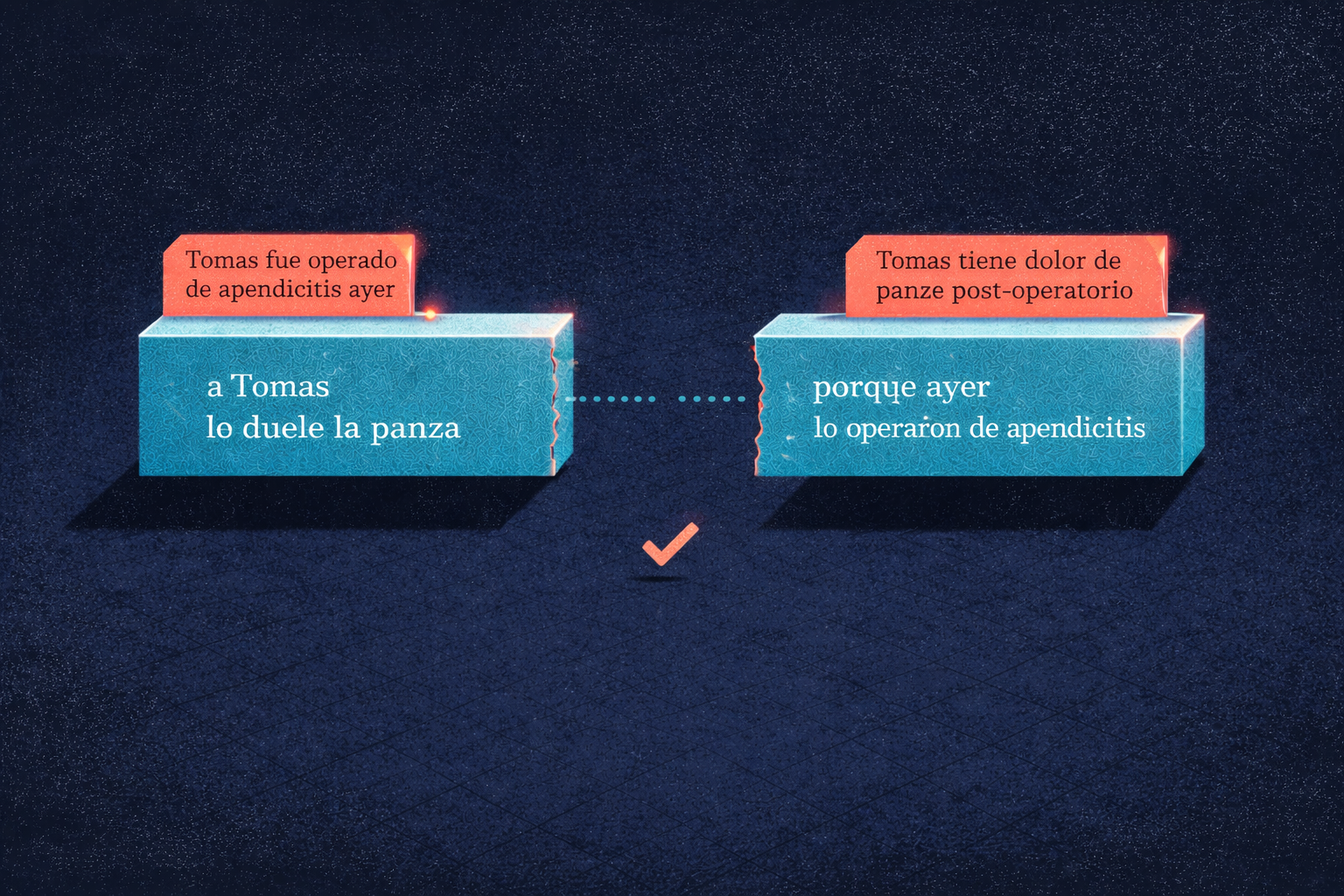
Este ejemplo parece medio boludo, los dos bloques tienen toda la info.
Pero imaginate una base de datos con millones de entradas.
Millones de conexiones.
Millones de direcciones.
Una frasesita en cada bloque que le da un poco de contexto a la info contenida adentro es oro en esas situaciones.
La LLM tiene de donde agarrarse para dar la respuesta completa o seguir buscando.
Casi que parece estúpido.
A veces me sorprende la simpleza de estas soluciones.
Me da alegría saber que cualquiera que se dedica al menos unos meses a investigar y entender un area puede revolucionarla por completo - sin necesidad de ser ingeniero.
+1 for "context engineering" over "prompt engineering".
— Andrej Karpathy (@karpathy) June 25, 2025
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window… https://t.co/Ne65F6vFcf
Pasando a 2025, Karpathy (de los primeros empleados de OpenAI y Director de AI de Tesla) postea este tweet, inmortalizando Context Engineering como una nueva disciplina oficial en el mundo de AI.
Quizás el problema no es tanto cómo preguntás (Prompt Engineering) sino qué ve el modelo y cómo lo usa.
"Context engineering means finding the smallest possible set of high-signal tokens that maximise the likelihood of desired outcomes."
— Anthropic
ACE: la punta de la lanza
Ya casi terminamos.
Si entendés todo esto y alguien menciona AI en un asado, vas a tener de qué hablar.
Todo genial entonces, Context Engineering es una disciplina formal.
Importa cuánto contexto le metes a un modelo.
Importa en qué orden.
Importa si es el correcto.
¿Cómo lo mantenemos?
Pensá que si tenés una conversación larga, como ya hablamos en otros posts, el contexto se va comprimiendo y desgastando.
Vas perdiendo calidad, los detalles.
Genial, le diste el mejor contexto del mundo, en el orden correcto, la longitud correcta.
Pero le hablas 10 turnos, 15 turnos a una LLM y su contexto pasó de ser
"Tomas tiene un Chevrolet Onix azul con patente AAA111 que se le pinchó la rueda derecha" a "Tomas tiene un auto roto."
No es lo mismo.
ACE (Agentic Context Engineering) plantea un sistema para mantener ese contexto vivo y relevante en 3 steps:
- Conversas con tu LLM (Generar)
- Preguntarse qué salió bien, qué salió mal, qué se aprendió. (Reflect)
- Actualizar el contexto con lo aprendido. Sacar lo irrelevante, reemplazarlo con cosas nuevas, dejar lo importante. (Curar)
Este sistema permite que tu contexto vaya mutando cuidadosamente en vez de que simplemente se "resuma" en cada iteración.
Ponele que mi agente me está ayudando a encontrar un lugar para reparar mi auto.
Quizás en el turno 5 de la charla con mi LLM, se dio cuenta que el color del auto no le importa para lo que estamos haciendo ==> Lo saca del contexto.
Pero si le mencioné que vivo en Buenos Aires ==> Lo mete en el contexto.
A estos cambios se los llama deltas.
Modificaciones de contexto propuestas que se analizan en el step 3 de Curación.
Obvio, todo esto requiere más gasto en AI, ya que cada paso tiene que usar una LLM y ejecutarse. Pero te juro que vale la pena.
Un ejemplito práctico
Esto deberías hacer vos para poner todo esto en práctica.
Paso 1
Creá un vault de archivos de texto (una carpeta que contenga files .md y más carpetas)
Así está el mío:

Paso 2
Hablar con el agente que quieras (Claude Code, Codex, Cowork, etc.)
Asegurate que pueda acceder a tu filesystem o al menos a la carpeta del vault.
Paso 3
Crea una skill que se llame /reflect-session o algo por el estilo.
Acá la que tengo yo:
Paso 4
Invocá la skill después de cada conversación o sprint con tu agente
Resultado
Todo lo que vos y tu agente aprenden es oficialmente tuyo.
Cada memoria, decisión importante.
El mapeo de tus proyectos.
Si Claude Code o Codex mueren, no se llevan tus memorias con ellos.
Las tenés vos y se la das al próximo agente, robot o humano.
"Lee mi vault en /vault", así de simple. Ahora tu nuevo agente tiene toda la info de lo que venís trabajando y no va a cometer los mismos errores.
Este sistema no es perfecto, pero tiene potencial y creo fuertemente que todos lo deberían tener.
Hasta la prox.